As renshuu has gotten more complex, the vocab search system is being used in more and more places - probably on the order of 10,000 times an hour.
As various features/improvements have been added to the search, it's gotten to where it can take too much (for me, at least) time to look stuff up, and I'm looking to simplify/redo some of the stuff to make it faster (which makes all of renshuu faster in the end).
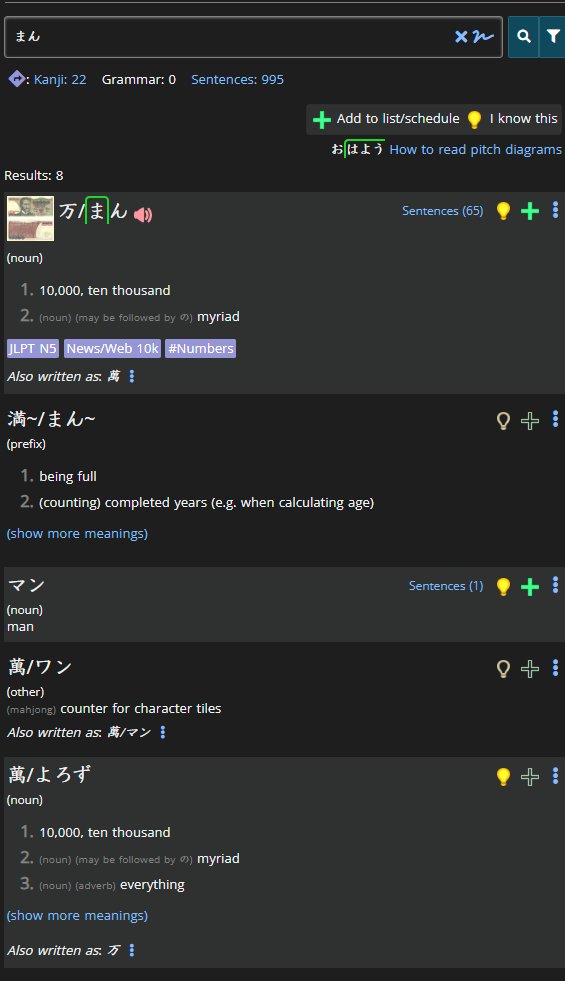
Currently, if you search for まん in the dictionary, you get this (roughly):
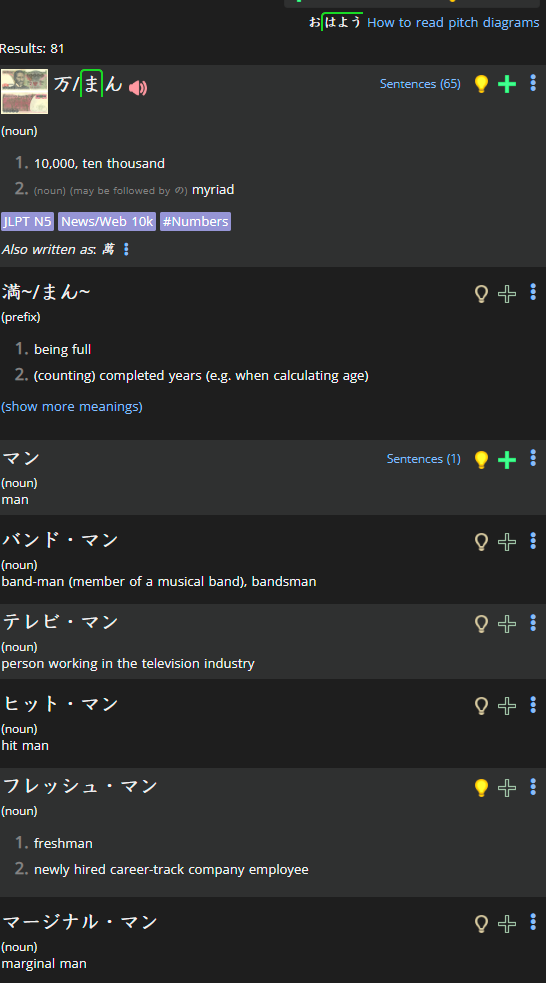
I'm considering a change that will keep the most important results up at top, but allow for "fuzzy" results below that. See:
This is actually just a fraction of the results, as you can see 81 terms were returned.
Thoughts? In terms of internals, this second panel removes an "expensive" check that I feel is maybe no longer needed.
I cannot give you the details without a lot of explanation, but for this particular query (which is very typical), there are no wildcards, so the check looks for entries that match the search perfectly (there is nothing before or after まん or マン). The second one, minus the check, allows for まん to appear within the results of other terms. It is not *too* fuzzy, though - for example, it does not return まんご. The underlying search engine seems start enough to do a good amount of filtering on its own.
And it's not actually 81 individual results: remember that count includes all the "also written as" entries.
Agreed, and it might be that I redo it to look that way, but I'm currently trying to keep it within the context of the current database setup for the search.
At the moment, the "japanese" field for a term like 食べる looks like this:
たべる 食べる
in other words, it includes the kanji and kana forms (there might also be other variations for other terms as well), so it's scanning along that line. A more complex example (あさごはん)
あさごはん 朝御飯朝御はん 朝ご飯朝ごはん あさ御飯 あさ御はん あさご飯
although you might point out that some of those are unrealistic, it expands out on all kanji permutations for any given word so it can catch as much as it can. This is all done with code, of course, and it doesn't make sense to go in and mark out specific ones. (they won't get searched on, anyway).
So I guess it may be the case of splitting all of these out into different rows in the search database. It's one of those things where I'd probably do a lot of things different if I were to rewrite it from scratch, but I'm seeing what kind of improvements can be done within the constraints of the current system. You've also got searches that involve both Japanese and English (not as common, but still there), so ..there's about a hundred different ways I could see all this data arranged in the db, and it's a lot of time to try them all out. (plus, of course, not wanting to disrupt a core function of renshuu).
Just did a little test, and I split up all those values into separate rows, but sphinx (the underlying search engine) is still saying "hey, these other words (like ヒット・マン) look close enough that they should be included. I suppose it would not have affected those, but it was worth seeing if anything changed.
It might simply be that the search engine needs a from-scratch rebuild, but I'm not sure if I have the willpower to do that anytime soon.
Multiple keys would be much faster, I’m sure. The trade off is that they need more space, but probably not enough to matter.
Unfortunately, there’s a decent chance that changing to that could break something that depends on the current behavior. Not a happy choice to have to make.
About all I can say is good luck with your experiments.