Looks like we might be waiting for a long time. Long story short (as I understand it) - this massive clipart site was run by a guy, built by another guy. The main engineer was killed due to political strife, and the person maintaining it seemed to tie the sight to the political views of this victim, so it got (has been?) DDOSed for weeks on end. Current guy doesn't seem to know what he's doing at all, and doesn't seem interested in taking the 100k + clipart released under public domain or whatever and putting it out there in a torrent so the work of thousands doesn't vanish off the Internet.
It is particularly tricky trying to follow along because the tweets put out often don't really seem to make sense, or sound as if different people are tweeting at different times.
Speaking of the difficulty with selecting images for certain terms, I've been having a dilemma about what kind of images to use for terms that have more than one distinct definition. Ideally, there could be a different image for each definition, but currently we're limited to one. Is it better to just not use an image for terms like 漕ぐ (used to mean to row or to peddle)? Or should I just use an image for any of the definitions, even if they are all equally used?
for cases like that, in my opinion one image for one of the meaning is better than no image. I see it like this: a begginner learning the vocab could use that one image to become very familiar with one of the meaning (as a basis) and then with time expand and learn about the other meaning one by one.
This said, would be pretty insane and awesome if the feature where to be upgraded so that when you hover your mouse over the meanings, would bring up the associated image :S Like meaning one would show one thing, touching meaning 2 would switchthe image to something else :S
Or like let's say for a vocab with 3 different meaning, all 3 images visible all at once, but when you touch one of the images, it highlight the meaning associated to that :S
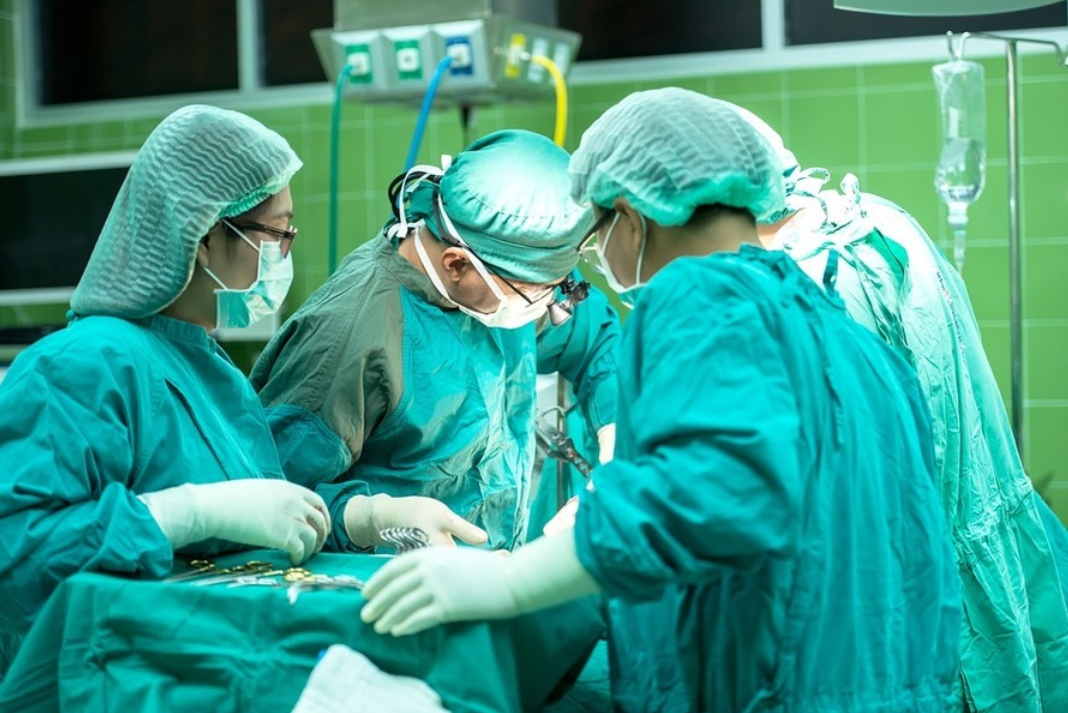
Someone put the image below for 医療, I am not familiar with the term, is that an appropriate image? whenI saw it I thought 手術 (I'm asking for confirmation before downvoting, since I'm not familiar with the vocab and unsure)
It's valid, but as Karlla said, there could be other images in addition to. I'm going to make it more obvious in the future that a term has multiple images.
Also, I love your enthusiasm about tying images to individual meanings - for now, I'd add anything that matches any of the meanings.
The tag says downvoted pictures won't appear again. Unfortunately, it doesn't seem to work. I've down voted two pictures but I'm still only seeing the easter eggs. If I add another picture it becomes the main for me, but otherwise nothing changes. This is happening on several terms.
might be because of the above fix, but where previusly I had visible all the standard images for vocabs submitted by other users, now is not showing them by default and I have to manually click "Picture" and upvote one of the users submitted ones. Given my schedule has around 5000 vocabs, it was better the previous way, where I only had to click a few mistaken ones rather than click on 5000 images myself :/
Small inconsistency: the default search term when trying to add a picture while on a schedule terms page defaults to the way the word is written in the dictionary, rather than how it is written on the page the term is displayed on. So, with my kanji settings the way they are, I see words written like 貴方 and 何時(いつ) in schedule term pages, but if I try to add a picture from there, the search box is autofilled with あなた and いつ.
I usually get different, and sometimes more specific, results by using kanji, yes. There are also a lot of words in the dictionary where the kanji is listed as rarely written, but writing the word in kanji is actually fairly common, so searching with kanji inproves the results, especially for words with homonyms.
I have begun to get more strict with the images that have come in. There's been two styles of pictures that I've been rejecting outright, but would like to hear your thoughts on it:
2. "Word as a title" images - they include the main word of the definition in a picture/photo, but the word is part of a title. For example, "革命" (revolution) may show a book that is titled "Revolution". The book may itself be about revolutions, but I feel the link is too tenuous. Another example - 結局 (end, in the end, etc.) got a picture of a road sign (in the darkness) that says "End" on it. Felt fairly vague and disconnected.
Doesn't the image for 続き fall exactly into that category?
You're absolutely right! The little tool I built for myself is not ideal, and I might have misclicked when I went through that one. Just marked it off.
I am uncertain, if this image of a fennec passes as a キツネ. Whereas a fennec is a type of fox, I wonder if Japanese people would actually call it kitsune?
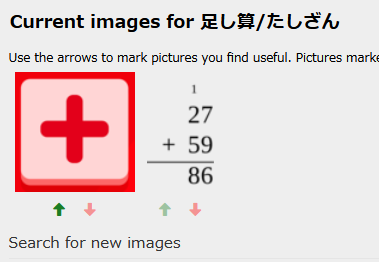
I had given the calculator button image (in the image above) to the four basic math operations, but for addition I am getting this even though the calculator button image is the one upvoted in my account And same with 引き算





 but I'm still only seeing the easter eggs.
but I'm still only seeing the easter eggs.  If I add another picture it becomes the main for me, but otherwise nothing changes. This is happening on several terms.
If I add another picture it becomes the main for me, but otherwise nothing changes. This is happening on several terms.