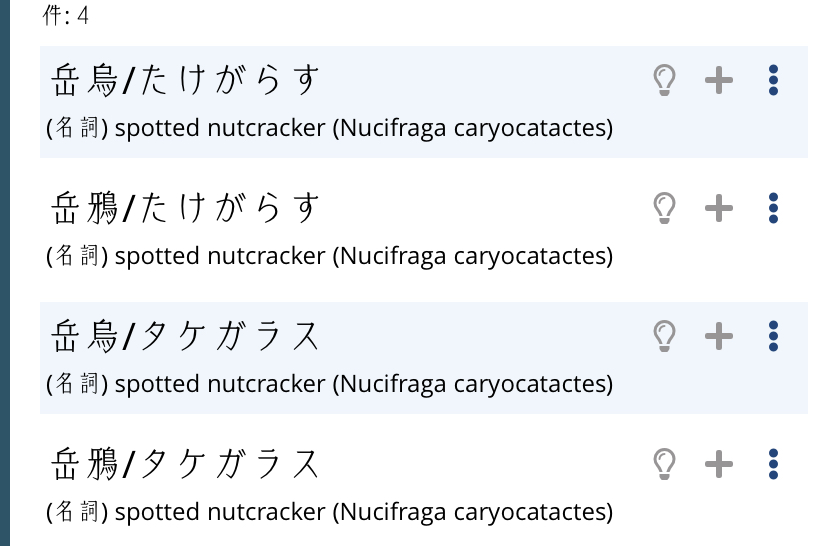
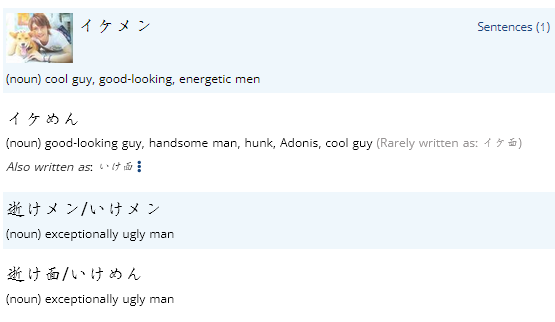
ふくろのねずみ has different dictionary results in the app from in the browser, but both sets of results have duplicates (app has 3 extra entries, browser has 1).
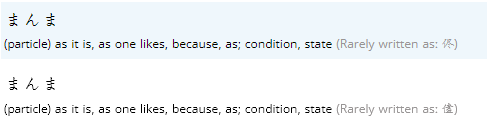
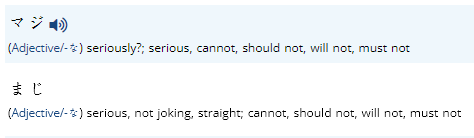
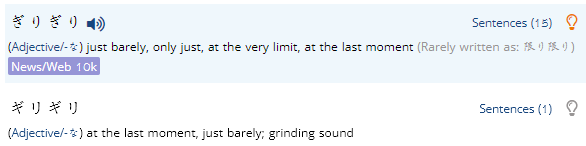
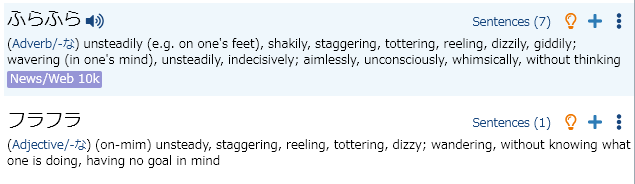
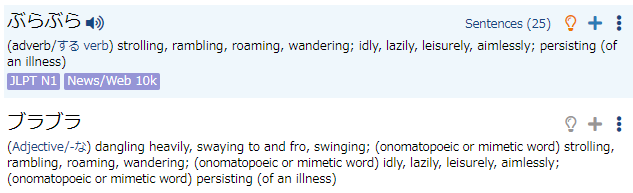
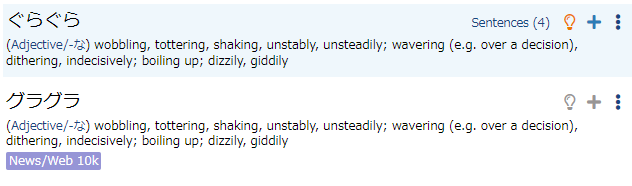
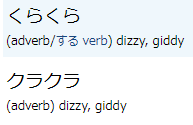
ふらふら, ぶらぶら, ぐらぐら, くらくら, ひらひら are also each duplicated, with one hira & one kata entry. (This seems to be true of almost all of the onomatopoeia entries... is there any way to do a batch fix to merge entries that only vary by hira/kata use?)
There are ways to do it in a batch, but there needs to be a ton of checks so that things don't get blended or merged so that they shouldn't. It'll take a lot of time to do, but is something I intend to work on at some point.
Edit: before that happens, I need to tighten my integration with JMDict, as there are a few gaps that I simply haven't gotten around to fixing.
Good eye, that’s easy to miss. If I understand the linked article correctly, it’s saying that a creature with a round head is mellow because it has no horns. It’s strange that the English version of Wiktionary has no entry for まろい, although it does have a (classical Japanese) entry for まろ which says it is missing an inflection table.
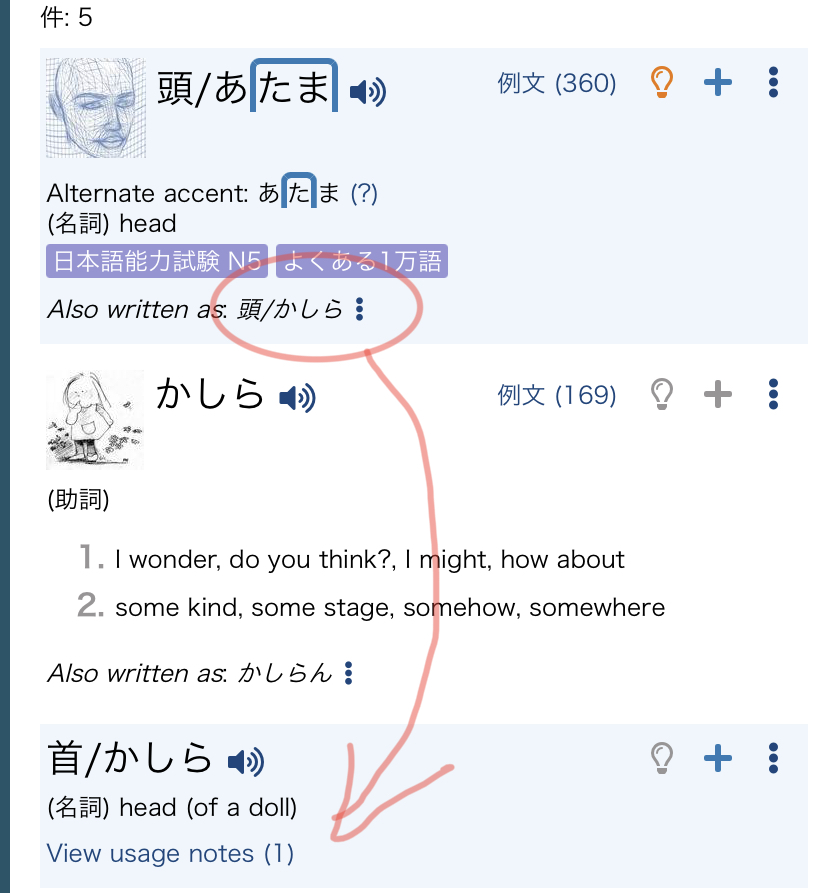
I was surprised to see あたま and かしら under the same entry. Is this a side effect of the database restructuring? Anyway, I think it would make more sense to have both kanji that are read かしら under the same headword.